"focus": ["Inference Infrastructure", "Kernel Optimization", "Compiler Correctness"],
"stack": ["LLVM/Flang", "vLLM", "CUDA", "C++23", "Python"]
Krish Gupta
Passionate about parallel computing, inference systems, kernel-level optimization, and building efficient AI infrastructure close to the metal.
- LLVM Project Member: Member with commit access, contributing merged work across Flang/OpenMP semantics, diagnostics, and regression coverage.
- vLLM Contributor: Working across inference runtime correctness, serving paths, issue triage, and reproducible debugging for real-world inference bugs.
- GSoC 2025 GNU Radio: Ported critical block families to 4.0 with ~2x throughput gains.
- Systems Performance: Built GPU roofline tooling, Slurm cluster ops workflows, and CUDA-adjacent benchmarking for performance analysis.
Selected Engineering
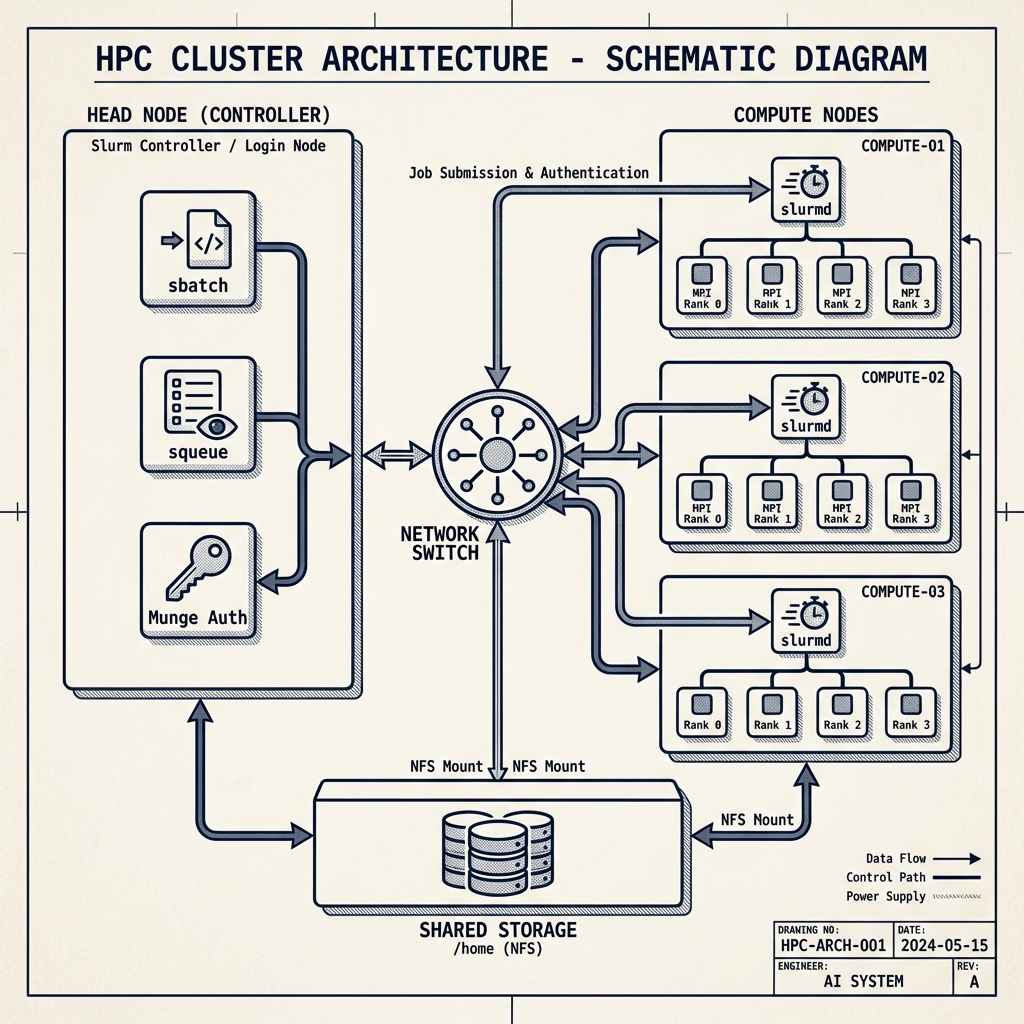
Slurm Mini-Cluster
Local simulation of a multi-node HPC cluster for job scheduling and parallel workload validation.
- Deployed multi-node Ubuntu cluster with Slurm + Munge authentication.
- Validated scheduling policies with real MPI/OpenMP workloads.
- Created comprehensive ops runbook for job triage and service recovery.
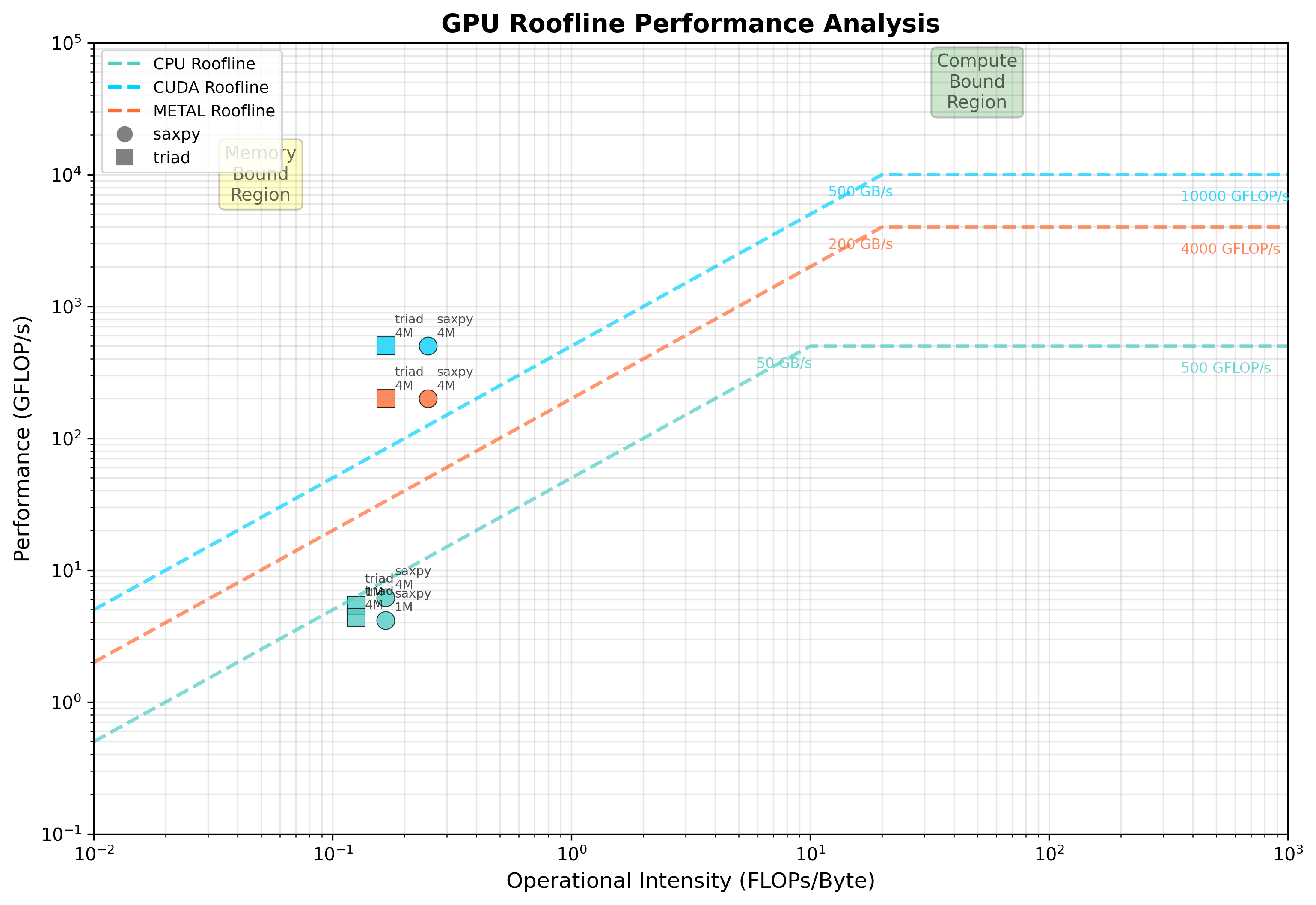
GPU Roofline Benchmark
A cross-platform benchmarking tool to identify bandwidth vs. compute bottlenecks across diverse hardware (CPU, CUDA, Metal).
- Built micro-benchmarks (SAXPY/Triad/SGEMM) for peak performance measurement.
- Automated device selection and roofline plotting logic.
- Supports heterogeneous backends (CUDA, Metal, OpenMP).
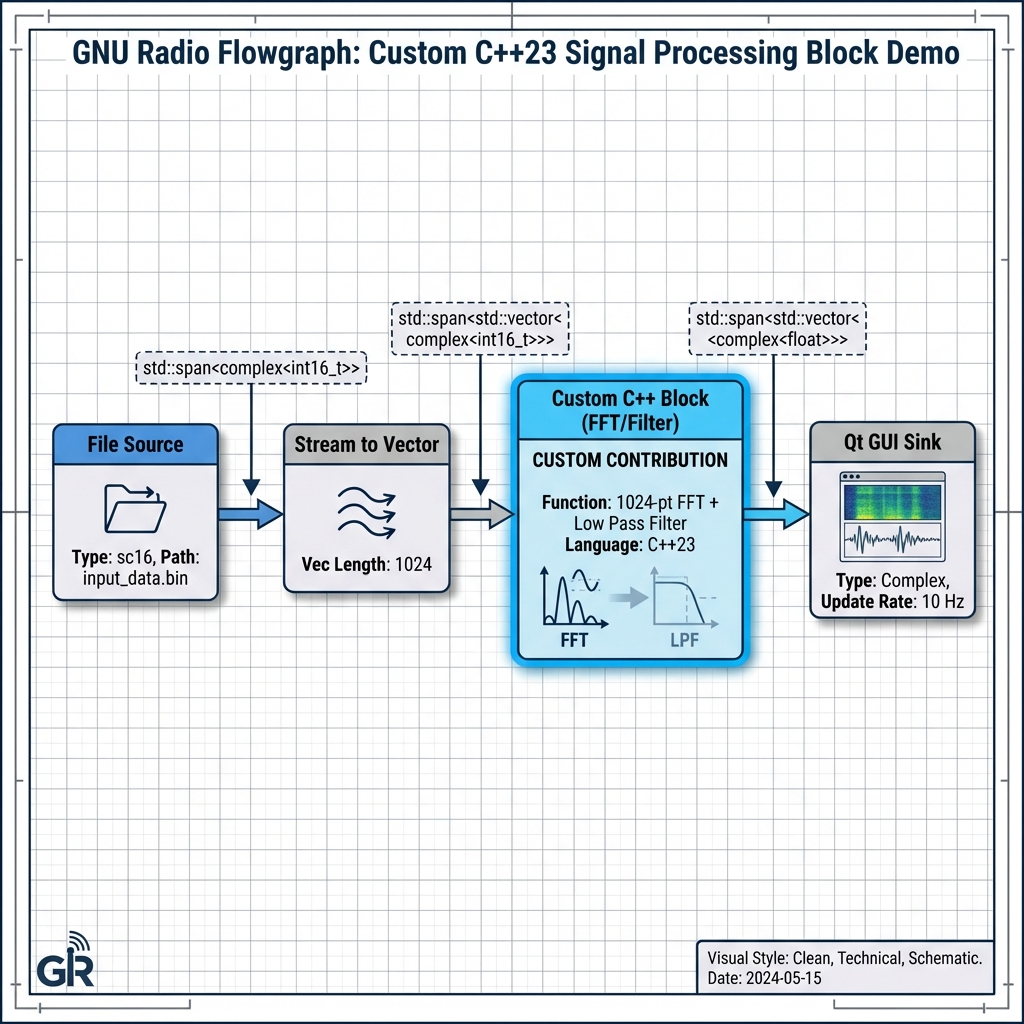
GNU Radio 4.0 Expansion GSoC '25
Ported and modernized legacy DSP blocks to the new modular 4.0 architecture, enabling high-throughput signal chains.
- Implemented Math/Analog/Digital families using C++23 template-registry patterns.
- Achieved ~2x throughput in targeted benchmarks vs legacy blocks.
- Added 75+ GoogleTest units and established CI regression baselines.
Building
Safety middleware for autonomous agents. Enforces deterministic output constraints and behavioral bounds for LLM-driven actions.
ReliabilityRequest coalescing backend. Implements Redis-based locking to reduce redundant upstream LLM calls and improve tail latency.
PerformanceOpen Source
LLVM project member with commit access, contributing to the Flang frontend with a focus on semantics correctness, diagnostics, and compiler reliability.
- Merged fixes across OpenMP semantics and diagnostic behavior.
- Expanded FileCheck and regression coverage for compiler correctness.
Contributor to the vLLM inference engine, focused on serving and runtime correctness, reproducible debugging, and systems-level reliability.
- Closed PRs across real inference-engine issues, grounded in reproducible local debugging.
- Working in the overlap of inference systems, CUDA-aware performance thinking, and runtime correctness.
Notes
Inspiration

"Be a net contributor to society."

"I’m convinced that about half of what separates the successful entrepreneurs from the non-successful ones is pure perseverance."

"Our greatest weakness lies in giving up. The most certain way to succeed is always to try just one more time."